Trusted by CTOs, Fractional CTOs, and CIOs from startups to publicly listed companies:








"StackUp is your secret weapon for staying ahead"

Steven Fulop
Director
xceltium
"an incredibly simple and efficient solution for our technology due diligence needs"

Jaron Yuen
Managing Director
MA Financial Group
"a game changer for driving our tech strategy forward"

Cody Harmon
Founder & CEO
Cruz
"so clear and useful"

Andrew Smith
CTO
Launtel
"unveiled crucial blind spots and areas for enhancement"

Ajay Unni
Founder & CEO
StickmanCyber
"identified critical risks in our tech infrastructure, including future obstacles to scaling."

Dhruv Jolly
Founder & CEO
TapOnn
"comprehensive and fast"

Justus Hammer
Co-Founder & CEO
Mad Paws
"identified risks, inefficiencies and improvements that SOC2 misses"

Angus Keatinge
Co-founder
Quickli
Built for leaders who need clarity, confidence and control over technology
For companies with $3M+ in revenue and < 1,000 employees

Fractional CTOs
Start every engagement with instant clarity. Spot risks fast, align stakeholders, and turn insight into trusted strategy.


CTOs / Tech leaders
Get an independent view of people, process and systems. Remove blind spots, align your team, and communicate with confidence.

VC / PE / Investors
See the true state of a company's technology in minutes. Assess risk and scalability to make faster, smarter decisions.

Board members
Get a clear, objective view of technology risk. See priorities in plain language so you can guide and govern effectively.
How it works
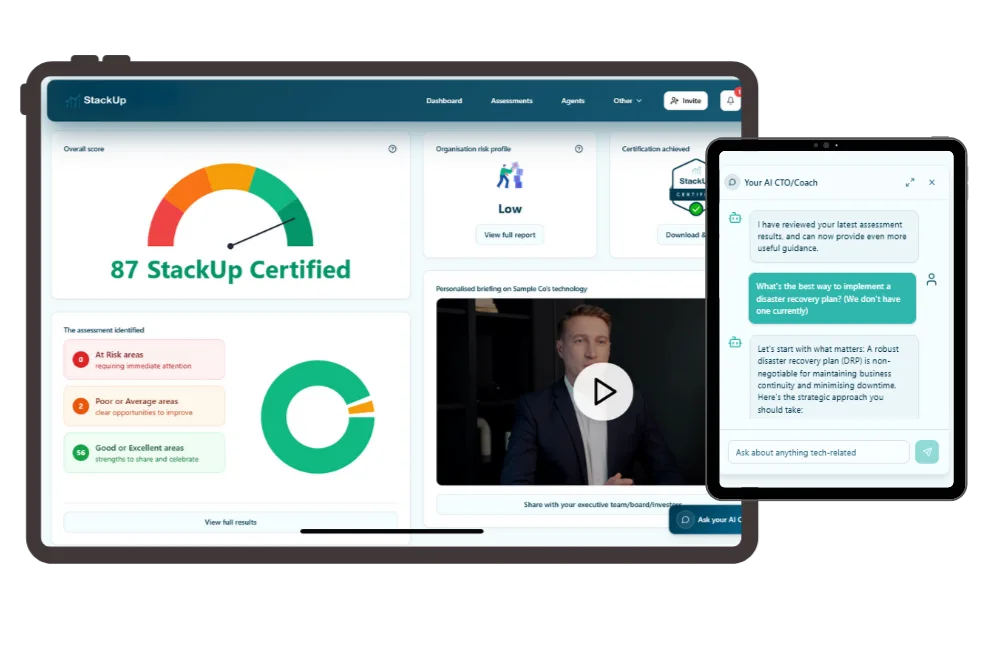
In 30 minutes, get an expert-grade diagnosis powered by decades of CTO experience - no integrations needed.
Assess
Answer focused questions across eight key areas to reveal risks, gaps, and hidden dependencies in minutes.
Analyse
Get an instant, independent report with prioritised insights, benchmarks, and clear next steps - no manual effort.
Act
Share findings with your team, board, clients or investors, and track improvements with ongoing reassessments.